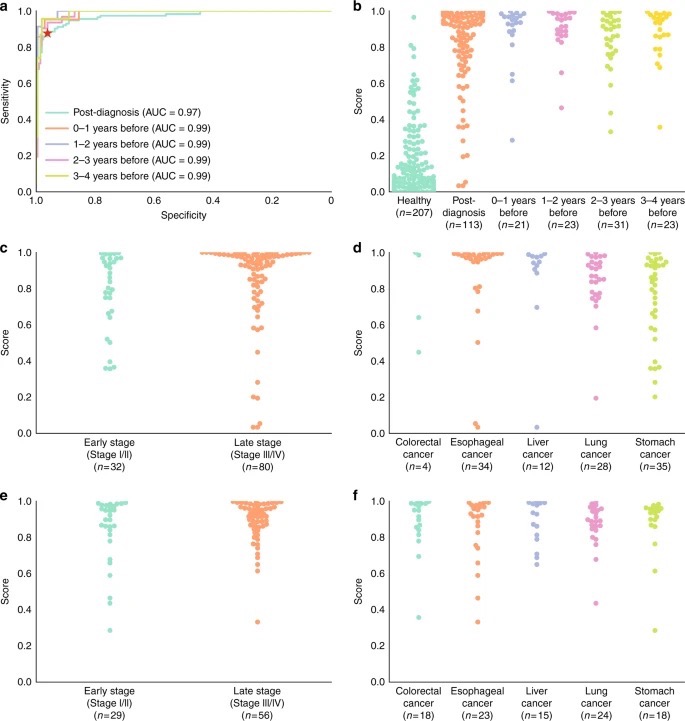
被屡禁不止的“论文工厂”仍在持续不断地输出造假论文。
近日,发表在《欧洲生化学会联合会快报》(FEBS Letters)上的一篇文章揭示了论文工厂的原始真相。2018年以来,经过作者对多篇论文的调查研究发现,目前有数千篇论文可能来自论文工厂。
作者指出了论文工厂造假论文的8大特征:具有相似的文本和结构;可能存在造假模板,图像数据会在不同文章中反复使用;原始数据图像来自不同模块的排列组合;引用文献与内容毫不相关;不同作者从同一台计算机提交手稿……
“论文工厂”造假论文:8个典型特征
2018年初,欧洲生化学会联合会(FEBS)出版社期刊编辑、德国海德堡大学生物化学中心的Jana Christopher等人发现了一种令人不安的潜在欺诈类型。一些论文手稿可能是按照某个模板来展示伪造数据的,这表明存在“论文工厂”:即出售假科学论文手稿的非法组织。
经过作者调查研究发现,自2018年以来,目前有数千篇论文可能来自论文工厂。
由诚信研究分析师、科学家、期刊编辑和记者组成的一个国际小组调查发现,论文工厂的服务可能包括数据捏造、出售作者、伪造同行评议和引用计划等。通常,这些论文手稿在多个方面都很相似,往往能顺利通过同行评审,且引用情况良好。
论文工厂对文献和后续研究的影响有多大尚不清楚。近两年,在生命科学领域大量可能出自论文工厂的论文被撤回。今年1月,英国皇家化学学会一次性撤回了68篇来自中国医院作者的论文,其中绝大部分出自知名大学或其附属医院。尽管如此,仍有数千篇此类论文尚待确定。
据报道,在伊朗、印度和俄罗斯等国均有论文工厂运行。除了生命科学领域的论文,也涉及人文社科、计算机科学和工程等领域。
Christopher指出,对于可能来自论文工厂的论文手稿,其指示性特征包括:
1.与其他论文/手稿的文本的相似性;
2.与其他论文/手稿在面板的组成和组织、注释样式、图表格式方面的相似性;
3.公式化的标题和结构;
4.杂志的稿件提交系统将稿件标记为,不同作者从同一台计算机提交;
5.作者使用商业的、非学术的电子邮件地址;
6.作者的ORCID ID(开放研究者与贡献者身份识别码)丢失或为空;
7.参考文献列表包含无明显原因的无关论文引用;
8.使用作者推荐的审稿人时,审稿时间异常短,且评审结果为肯定。
案例解读
案例1:论文工厂或存在造假模板
论文工厂似乎有论文模板,在几篇不相关的论文中,其文本、表格、图形的总体布局和设计十分类似。其图像数据被重复使用,不仅限于蛋白质印迹、显微照片等,还包括表格、散点图、条形图,甚至是数字。
图1显示了2018年10月,在《皇家学会开放生物学》上发表的两篇不相关文章中的重复图像和具体数字,分别用蓝色和紫色框标记,这两篇文章来自不同的作者,都在2020年7月被撤回。

源自欧洲生化学会联合会快报(下同)
案例2:引用文献与内容毫不相关
可能出自论文工厂的论文还会互相引用,这增加了它们的可信度。
最近提交给FEBS的一份论文手稿中,描述了miRNA、靶点及在特定疾病中的作用,参考文献列表引用了几篇文献,但这几篇文献中既没有miRNA、也没有靶点、更没有相关疾病机制。这表明,这些论文纯粹是为了引用而列出的。
仔细检查4篇被引用的论文后,Christopher发现,每篇文章都包括一个条形图,值与新提交的论文手稿中的一个图形相同,但标签不同,设计和颜色也有所改变,见图2。这4篇文章来自中国不同医院的不同作者,发表在2种杂志上,Christopher等及时提醒了他们。

案例3:原始数据图像的背景和内容可随意组合
对于Christopher等检测论文工厂论文工作而言,围绕图表的原始数据制定一项强有力的规范至关重要。
Christopher等还观察到,免疫印迹的原始数据经常会被操纵或完全捏造。据报道,生成对抗网络(Generative Adversarial Nets,一种基于人工智能的图像合成技术)可以通过计算机生成外观极为逼真的蛋白质印迹,创造出人们通常所称的“深度假货”。
图3显示了最近被撤回的一篇论文中的“原始数据”,这篇论文是在Christopher为其它杂志所做调查后撤回的。在PS中打开图像数据文件显示,在每幅图像中,这些条带都与背景在不同的层,也就是说,可以任意将不同行的条带与假背景结合,这可以生成25个代表了不同实验的单独图像。这个案例中,因为原作者没将这两个图层合并,因此可以清楚地追踪。

案例4:需要原始数据时,论文工厂现做现发送
2018年,FEBS出版社的2家期刊收到了12份来自论文工厂的投稿:论文图像中所展示的免疫印迹的背景噪音在多个图,甚至多个手稿中都是相同的。这批手稿在短短几周内,分2-3批提交。后来,被FEBS出版社拒稿后,这12篇文章在其它期刊发表。
这些文章后被列入“蝌蚪论文工厂”清单,该清单由著名学术“打假人”Elisabeth Bik等列出,确定了近600份显示具有模板背景的特征性蛋白质印迹的论文。尽管这些图片看起来非常相似,但目前还不清楚所有这些论文是否来自同一个或多个论文工厂的模板。
这些例子表明,在缺乏真实数据的情况下,论文工厂为了向期刊提供原始数据,可能需要制作图像。
案例5:7篇论文同时出现低级错误
2020年,Christopher受命协助调查在FEBS以外的期刊上发表的大量论文。在被调查并最终撤回的论文中,Christopher注意到,几篇不相关的论文作者提供的免疫印迹原始数据存在相似性,数据呈现和排列等要素都非常相似,这几篇论文的作者没有重叠,彼此也没有从属关系。
图5展示了这6篇论文的原始数据图像,这和在同一时间提交给FEBS出版社的一篇论文的免疫印迹原始数据呈现模式相同。这7项研究没有联系,但其原始数据都有相同的布局:三个并排重复,每个印迹板中心的条带位置相似,所有图像的右上角都被以数字方式裁剪掉了一块。

(A,B)6篇论文中的2篇的免疫印迹原始数据。(C)在同一时间提交给FEBS出版社的一篇论文的免疫印迹原始数据。
值得注意的是,所有图像的右上角都被以数字方式剪掉了一块。
在免疫印迹中,通常做法是将X射线胶片的一角剪掉,以确定胶片冲洗后的方向。这是物理的,也就是用剪刀剪掉。
然而,在这些例子中,裁剪是以数字方式完成的。可以想象,这是为了使图像显得真实故意这么做的,但如果不使用X射线胶片成像,使用数字成像的话,完全没理由这么做。
内容来源:科学网

 上一篇
上一篇